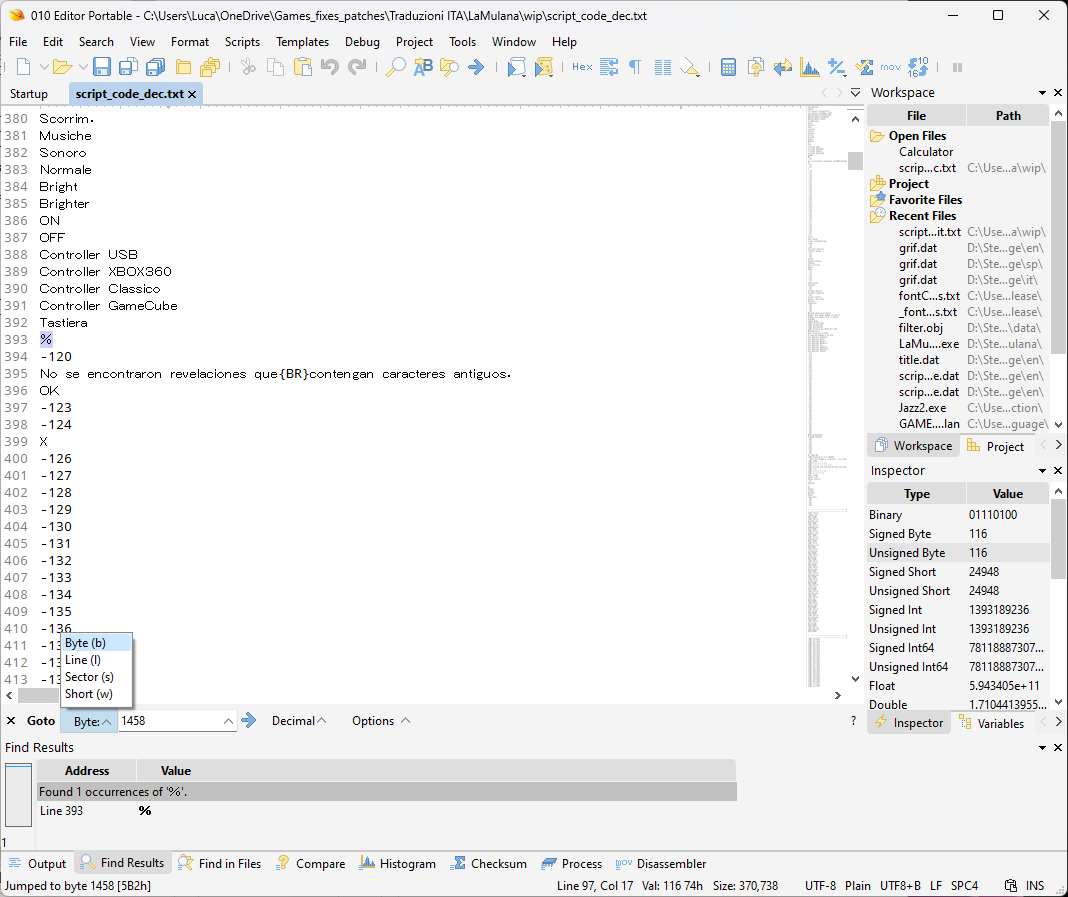
Today I needed to find an error at a Character Number from the beginning of a complex text file using strange chars in a UTF-8 doc (i.e. sometimes a char uses 3bytes UTF-8, some others 1byte ASCII in the same doc, apparently), and noticed such an option is missing (you can search by “Byte, Line, Sector, Short”):
Hello hexaae. 010 Editor can go to a column from the beginning of a line, but not currently to a character from the beginning of a file. If you want to go to a column from the beginning of a line you can use the Goto bar with Ctrl+G and for example you could goto line ‘5|3’ to go the the 5th line and the 3rd column. The column number should be the same as the character number on the first line, unless there are tabs on the line.
If you want to go to a character number from the beginning of the file that is something we’d have to add in. I’ve not actually seen that calculation in other editors and it’s a little ambiguous, since I guess you have to skip linefeed characters and do you treat a tab as 1 character or multiple characters?
If there are no tabs you could do the calculation in a script if you need this now. You could figure out the end address on each line using TextLineToAddress and TextGetLineSize and then call TextAddressToColumn and add up each column until you get to the desired point. If you want to do this and can’t get it working we can write a short example.
It would be great for cases like these, yes please, would be a very useful option in these circumstances… I think an option to include/exclude linefeed chars in the calculation, and an option to define also TAB length for this “goto char number” would be perfect…
It can be very helpful, even though I must admit it’s the first time I encounter a doc with mixed char encoding in a single file: 3 bytes (UTF-16 ?) mixed with 2 bytes UTF-8 and 1 byte ASCII in the same doc file (!) as shown in the pic below (char “u” = 1 byte, char “a” = 3 bytes (UTF-16, U-FF41):
With mixed byte length chars like this in a single file it’s impossible to calculate the “position of char 1458” for example. That’s why a specific “goto char number”, and not by byte, would be a very handy unique option…